|
Нови комуникационни архитектури - информационни данни и компютърен „облак”
доц. д-р Руси Маринов
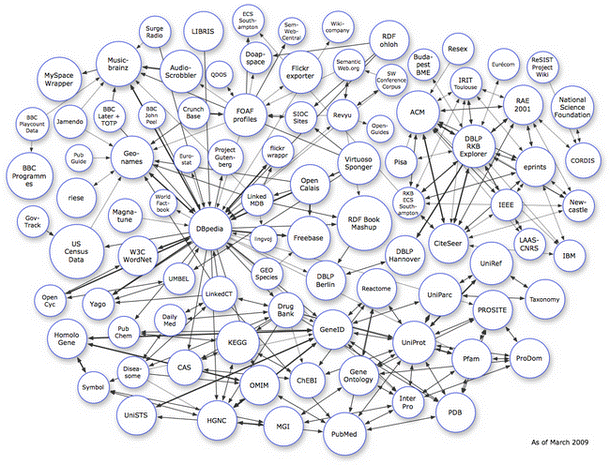
В последните няколко години наблюдаваме революция относно способностите на машините да обработват, класифицират и организират приложна информация. Това ново явление е свързано с развитие на семантичната мрежа в няколко основни направления: Мрежа от данни, Мрежа от услуги, Мрежа за идентичност и Мрежа в реално време. Тези тенденции предполагат и нови подходи за анализи, изследване на информационния поток, както и други по-различни програми за обучение на студенти, тренинг на служители и мениджъри. Идеята за изграждане на мрежа от данни прозхожда от опитите да се изгради семантична структура на съществуващата система. Експертите се опитват да разрешат проблемите, свързани с неспособността на машините да разбират елктронните страници. Основната цел на семантичната мрежа е да представя анотирани страници с помощта на мета-атрибути и категории, за да се даде по-голяма възможност на машините да интерпретират текстовете и да ги поставят в подходящ контекст. Този подход се оказва неуспешен, защото анотацията е твърде сложен за хората процес, особено за онези без необходимата технологична подготовка. Новите подходи са ориентирани в посока подобряване на машинния достъп до знание, закодирано в страници, предназначени за ползване от експерти. Друг проблем е, че някои страници съдържат излишна информация, неразпознаваема от машините. Именно идеята на Web of Data(Вж, схемата) идва като резултат от всички тези проблеми и ограничения, както и от съществуването на огромно количество несвързани данни, разпръснати по целия свят. Обикновено групите от данни съдържат знание относно конкретни области и са от типа: книги, музикални, енциклопедични данни, бизнес резултати, които са изолирани помежду си. Ако успеем всичко това да го свържем по подобие на линковете между уеб страниците, тогава машините ще могат по-ефективно да обработват информацията и знанието в конкретни области. Този процес се превръща в глобален и генерира появата на нови услуги, идеи и приложения.
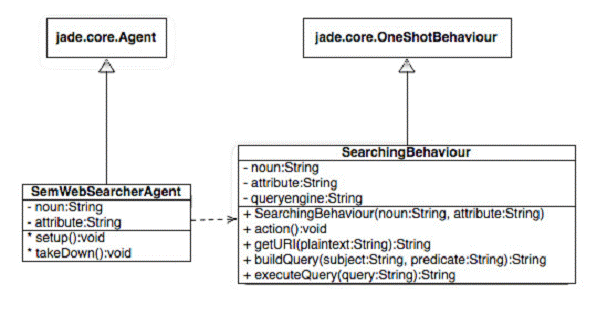
Според изследователската група Форестър[1] в близките 3-5 години новото поколение мрежа от типа Web3D ще осигури една интерактивна, емерсивна среда, много по-богата за потребителя, отколкото съществуващата в момента. Технологията ще надхвърли използвания сега статичен, ориентиран към текста, графичен интрефейс.Web3D ще позволи на хората да се представят визуално, с помощта на аватари, които могат да се движат в пространството, да общуват помежду си, да взаимодействат с други обекти и информация - да изградят един нов дигитален свят, приличащ на реалния. При тези случаи възможностите на платформите и медиите, ориентирани към знането ще бъдат още по-големи и по-ефективни(Вж, схемата). Например, MapReduce е софтуерна рамка, развивана от Google, за да се унифицират множеството данни в съвременните мрежи. Тази технология е ефективен инструмент за ориентиране на потребителите в огромния поток от данни в дигиталната епоха. За разработване на приложението се използват езиците Java, C#, Python, C++ и R, като се създават общи места за съхранение на данни, под формата на кластери. Хората могат да задават въпроси на машините, с цел получаване достъп до информация, която по-рано беше недостъпна. Функции на системата: @откриване на измамна, подвеждаща информация, в рамките на 90 секунди; @графичен анализ на социалните мрежи, с помощта на фунцията nPath, за да се установи как се свързват помежду си потребителите в една общност; @споделяне на мнение и поведение с помощта на техниката ShareThis, за ограничване времето за анализ на поведението; @организиране на сесии-социални мрежи; използващите тази фунция могат да разделят данните на отделни сесии и дефинират активността на потребителите; @трансформация - бърза промяна на данните, опростяване на кода при представянето на информацията. Семантични, интелигентни устройства Според концепциите на управление на знанието (известни още като КМ платформи) данните, информацията и знанието са взаимно свързани величини. Ще посочим някои популярни дефиниции за тези понятия, намерили отражения в специализирани, научни електронни библиотеки: данни - факти и цифри, представени извън контекстта; мрежа от дискретни и обективни факти, които не отдават значение на случващото се; информация - данни, представени в определен контекст и готови за използване. Данните се превръщат в информация, когато им се предаде значение; информацията още е тип съобщение; знание - информация, която ни ориентира към действие и реализиране на цел; включва още правила и контекст; знанието е по-богато и по-задълбочено от информацията и данните, усъвършенства се с помощта на опита; хората могат да трансформират информацията в знание. По-горните понятия(Вж. Електронно ръководство ”Стратегически комуникации и знание”.НБУ , 2009) непрекъснато се доуточняват, за да може да се унифицира езикът между машините и човека. Така например, информацията е мярка за неопределеност или за ентропия. Колкото е по-голяма неопределеността, толкова е по-стойностна информацията. Когато ситуацията е напълно предсказуема, в действителност липсва информация. Повечето хора, обикновено, правят асоциации между информация, знание и определеност, което противоречи на информационните теории.Съгласно схващанията на теoретиците по информация, концепцията няма отношение към съобщението, фактите или значението. Информацията - има отношение към квантифициране на стимулите или сигналите в дадена ситуация. Другото разбиране на тази теза е информацията да се разбира като необходим брой съобщения, които могат да редуцират неопределеността на дадена ситуация. Информацията е комплексен термин, с латински корен"informatio" - предавам форма на нещо. Този термин ни отвежда към гръцката онтология и епистемилогия, към концепцията на Платон за "идеята" и на Аристотел за "морфос" или формата.Тези термини в модерните времена се модифицират в концепцията OED или - процес на технологична комуникация, водещ до получаване на знание. Някои съвременни автори казват, че съобщението се съотнася към значението, информацията към селекция в определена система, а разбирането към възможността за интегриране на селектирани данни с предварителното знание. Знанието от своя страна е начин, подход за селектиране на значение в определена физическа или социална система.Още е процес на комуникация, с цел формиране на модел за мислене или вникване в същността на нещата. Казано с други думи, представянето на знанието е информация. Знанието включава още данни и отношение между елементите на данните. Известно е, че информация, знание, комуникация са важни части от съвременните медии. Медиите от ново поколение представляват една модерна, съдържателна и по-качествена платформа, разработвана от екипа на Тим Бернърс Лий, като дизайнът на модела ще бъде ориентиран към акумулиране на знание, към семантични структури и информацията ще бъде подредена под формата на онтологични речници и специални web agents ще изпълнявaт заявки за търсене вместо човека. Достъпът и ползването на новите медийни ресурси ще става само с помощта на аватари или дигитални двойници на хората. Целта е изграждане на едно пространство на взаимосвързани данни и знание, което да замести сега съществуващата мрежа на свързване на отделни документи. Тези направления все още са далеч от организиране на задълбочени изследвания в България, още по-малко новите реалности не са включени в достатъчна степен в програмите за обучение на студенти и нищо чудно страната ни да изостане значително от новите тенденции, което е факт и в момента, в близко бъдеще. Самото понятие „комуникация” се използва много често за обозначаване на процеси, където липсват комуникационни технологии и терминът се е профанизирал. Това състояние заставя изследователите да търсят други по-адекватни думи за обозначаване на процесите по извличане и предаване на информация и споделяне на знание. Новите семантични мрежи са базирани на знанието. Целта им е да създават, търсят, манипулират и генерират знание. Ключова технология, използвана в Semantic Web е езикът RDF, разглеждан като графичен и обектно-ориентиран модел за представяне на знание. Според разработките на Ай Би Ем от 2008 г. нови интелигентни агенти ще свързват отделни данни в мрежата като я трансформират в семантична. Още тези своебразни, софтуерни програми (Intelligent agents) предстваляват затворена, компютърна система с определена архитектура и следните характеристики: o разположени са в определена среда; o могат да възприемат информация от средата; o напълно са автономни и са вписват в средата; o имат определени цели. Всяка интелигентна система има четири основни части: измерителна; силово устройство; сензорна и системна. Семантичните агенти се подразделят още на: интерфейсни; мобилни; информационни; самообучаващи се; роботизирани. Това означава, че могат създават пълна картина на реалността и в зависимост от промяната на средата могат да вземат решения и предприемат определен тип действие. За нас особен интерес представляват комуникационния тип агенти, които са мултифункционални устройства и могат да обменят опит и знание. Технологичната фондация FIPA (част от Международната организация по стандарти в областта на електронните технологии) е формулирала стандарти и препоръки за изграждане на такъв тип системи. Тези агенти са изградени на базата на онтологии, използвайки езика OWL (Web Ontology Language). Възможните функции на тези мрежи и интелегентни устройства са: трансформиране на документите във формално знание, публикувано в мрежата; създаване на групи и мрежа от общности, ориентирани към определен тип знание; изпълняващи ролята на персонален помощник (например на лекари или учители); самостоятелно търсене на информация и вземане на решение. По-долу прилагаме графичен модел на системата:
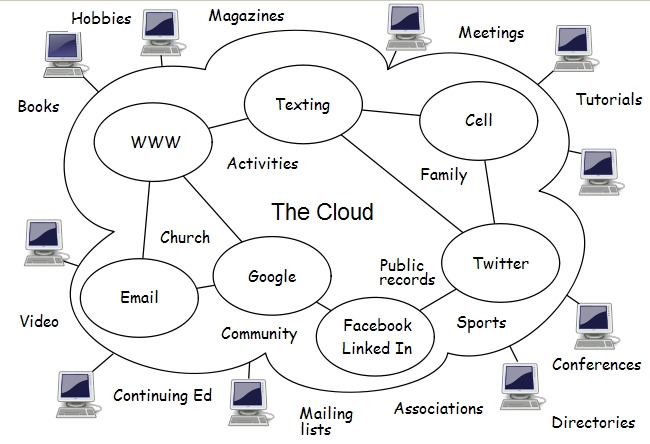
Днес някои от най-използваните технологични продукти в посочената по-горе сфера са следните: Sesame, Jena (специализирана библиотека за RDF ресурси), Jade (метод за програмиране на агенти, използван от FIPA), ALBE (съдадена методология от IBM за изграждане на среда за обучение). Напоследък wikis страниците намират голямо приложение при структуриране и управление на знанието. Wikis позволява на потребителя да прави линкове от една към друга страница и тези връзки се използват за навигация, с цел споделяне на релевантно знание. Семантичните wiki (комбинация между семантична мрежа и wiki технологии) дават възможност да се правят формални описание на ресурси, чрез анотиране на страници. Структурата (Вж схемата) на тези технологии се състои от следните компоненти: потребителски интрефейс; синтактичен анализатор; сървър за страници; анализатор на данни; склад за информация. Навигацията в мрежите се осигурява от метаданни, структурирани по подходящ начин, т.е. достъпът до информация става с помощта на специални браузъри. Популярни средства в областта на семантичните wikis, използвани за управление на знание, съдържание и комуникации: Ontowiki; Ikewiki; GATEWiki. Data mining[2] или извличане на данни представлява нова технология за откриване на знание в база данни (KDD). Процесът още е свързан с не-тревиален подход за достъп до имплицитна, непозната досега и потенциална полезна информация. За целта се използват специални машини, образователни, статистически и визуални техники за откриване и предствяне на знание във форма, която е достъпна до хората и разбираема. С други думи тази технология е свързан с използване на модерни компютърни технологии за достъп до знание и информация и предаване на смисъл на данните, т.е. да бъдат обвързани с практически цели, разработки и проекти. Проектът за семантична мрежа е свързан непосредствено с извличане на данни и предаване смисъл на информацията, съществуваща в мрежите. Необходимо е още да се прави разлика между отворен тип данни (Open data) и свързани даннни (Linked data). Това означава, че голяма част от данните могат да бъдат достъпни до хората и публични, но от друга страна не са свързани с адекватни ресурси в мрежата. Тим О’Рейли заявява, че бъдещето принадлежи на тези, които разполагат с повече съхранени данни, както и тези, които имат възможност да извличат значение от данните и да го доставят в реално време на краен потребител. Можем да проследим няколко важни етапа в развитие на технологиите по обработка на информацията и съхранение на данни: Първи етап - събиране на данни (1960), технологията е базирана на компютри, дискети и магнитни ленти. Втори етап(1980) - достъп до данни/технологии базирани на SQL, ODBC, с доминиращи компании-Oracle, IBM, Microsoft. Трети етап(1990) - Съхранение на данни - създават се специални складове за информация от типа на Relational Data Warehouse, OLAP, MDDB. Доминиращи бизнеси - Business Objects, COGNOS, Hyperion. Четвърти етап(2000) - Управление и извличане на данни, базиран на технологии от вида на Advanced algorithms. Доминиращи бизнес компании - SAS, SPSS, IBM, Oracle, NCR. Основната характеристика на този етап е ориентирана към действия информация, с акцент доставка на знание. И последният етап е технологията от типа на "компютърен облак", с перспектива за динамично развитие в близките няколко години. Основната характеристика на модела е голямо разнообразие от информационни ресурси, бърз достъп до тях, споделяне на програми и знание, осигуряване на данни в реално време. Мрежа в реално време За изграждане на мрежи, които показват не статична информация, а информация в последния час се говори от няколко години. Tози модел предполага също промяна на съществуващия стандарт HTTP и въвеждане на ново поколение езици и сървъри от типа на XMPP. Първият стандарт осигурява търсене на информация в база данни, а вторият отразява реални неща, които се случват в момента. XMPP е ориентиран към индексиране на информация и получаването в точното време и на точното място. Такава технология беше Google Wave, но за съжаление поради комплицираната си структура не намери приложение на пазaра, но google продължава да се интересува от този стандарт и заделя много реусрси за усъвършенстването му. Целта на проектите е в бъдеще да се премине от "мрежа от страници" към "мрежа от хора". Информационният поток и прекаленото голямо количество информация, която трябва да бъде обработена се явява основна пречка за успешното управление на организацията. Претоварването с информация е породено не само от огромното количество съобщения, обем на текстовете, но и от качествени аспекти на комуникацията като неяснота и разнообразие на потока. Комуникаторите правят всичко възможно за подобряване на информационния поток и ролята на информацията при вземане на решения. Едно изследване[3], проведено през 2009 г. от IABC сред 16 водещи в технологично отношение компании в света, сред които са Майкрософт, Проктър енд Гембъл, Ай Би Ем, Нокия, ИксПлейн, Башиба и други показва, че имат разработени технологии за управление качеството на потока и ограничаване на времето за четене на съобщенията. Брой на изследваните лица 568. Изследването още показва, че въпреки високия професионализъм не използват съвремении подходи за структуриране на информацията и потока, и имат сериозно проблеми в това отношение. Важно условие за подобряване на ефективността на потока е търсенe на модели за визуализиране на информацията и идеите. Ето някои резултати от изследването, като в случая се използва скала за отговори („напълно съгласен от 1 до 5” и „напълно несъгласен от 1до 5”) : На въпроса „Каква е ползата от визуализация на комуникацията?”, представителите на компаниите отговарят по следния начин: · Компресиране и синтезиране на информацията - 4.07; · Разделяне на различни типове информация и показване на връзката помежду им - 4.07; · Да се направи информацията по-разбираема - 4.01; · Да се доставя по-бързо информацията - 3.99; · Да се добави стойност към съобщенията - 3.87; · Да се подобри запомнянето на съобщенията - 3.81;
На друг въпрос „Използва ли се визуализацията на информацията от комуникаторите в бизнеса?”, отговорите се подреждат по следния начин:
Трети въпрос „Коя е най-важната причина, за да не използвате визуализация?” Отговорите се подреждат в следния порядък: § Не разполагаме с достатъчно време за визуализация - 3.88; § Липса на елементарни инструменти и програми за визуализация - 3.79; § Липсва необходимия дизайн и „ноу-хау” за визиуализиране на информацията; § Моделите за визуализация са доста трудни, за да бъдат използвани - 3.13. На базата на тези резултати се препоръчва от Международната професиoнална организация по комуникации (IABC) един класически модел, състоящ се от 7 стъпки, за да се редуцира влиянието на свръх-информация: 1. Информацията да бъде навременна - да се осигури тогава, когато е необходима, да се избягват пикови моменти; 2. Подготовка на кратко резюме и сбит преглед на текстовете - с цел разясняване на аудиторията, кое е важното и на следващия етап да се осигурят повече детайли; 3. Визуализиране - използване на прости систематични диаграми и визуални метафори за обобщаване на съобщенията и оказване помощ на аудиторията да открои главните точки; 4. Последователност и ясна структура на иформацията - използване на унифицирана структура при подреждане на съобщенията, за да не се губи време за ориентация, кое къде се намира; 5. Персонализиране - информацията да бъде съгласно предпочитанията и потребностите на хората, съобразена с интерсите и задачите, които изпълняват; 6. Да бъде интерактивна - комуникацията е двустепенен процес, хората да бъдат ангажирани по някакъв начин с информацията и съобщенията. 7. Да бъде достъпна - използване на илюстративни метафори, прости аналогии, интригуващи истории или примери, с цел вникване в комплексното съдържание и ограничаване претоварването с излишна информация и детайли. Вижда се, че посочените по-горе нови ориентации и технологии могат да променят из основи съдържанието на медиите (което вече е базирано на основни линкове, кореспондиращи със съдържанието и усилена виртуална реалност). Появява се нов терминологичен апарат, нов начин за изразяване и по-различен подход към интерпретиране на информацията. И тъй като ние почти винаги изоставаме от тези тенденции, както медиите, така и образованието ни отразява един контекст и начин на изказ, типичен за миналия век. За да съществува какъвто и да е тип комуникация е необходимо да разполагаме с технологична инфраструктура, която да осигурява нормален и адекватен на реалностите информационен поток. От тази гледна точка, в момента делът на информацията в българските медии е около 5-6 процента, останалото са данни и неинтерпретирани факти. Смята се, че информационната система „облак” променя света на комуникациите и осигурява повече възможности за развитие на малки и средни иновационни компании. Този тип технология се дефинира като модел за съхраняване, управление, организиране и достъп до информация и други данни, съхранени на специфичен сървър. Изчисленията под формата на облак е бързо развиваща се област на компютърните науки и се нарича по този начин, тъй като данните и приложенията съществуват под формата на „облаци”, записани на на уеб сървъри. Системата има две секции: front end и back end, свързани помежду си чрез мрежа, обикновено Интернет. Първата част е ориентирана към клиент/потребител, а втората е самия облак. Съществуват два структурни елемента, осигуряващи ефективно функциониране на технологията. Първият включва мрежата на клиента или компютрите му, както и програмите, които се използват за достъп до база данни или сървърите, съдържащи всички данни. Вторият елемент от архитектурата е самият „компютърен облак”, където се съхранява цялата информация, съхранена на сървърите, до които клиентът желае да има достъп. Тези два елемента на архитектурата са свързани в обща мрежа и осигуряват контролиран достъп на всички потребители до облака, без да се нарушава сигурността и надеждността на данните. Терминът "облак" се използва още като метафора на Интернет технологиите и показва по какъв начин се изобразяват формите на мрежовите диаграми. Интересът към тази терминология, съгласно анализите на съдържанието в google, се засилва през последните 2 години, графиката на рейтинга се покачва непрекъснато от 2007 г. до настоящия момент. Страни, които проявавят засилен интрес към технологията са Сингапур, Индия, Хонг Конг, Тайван и САЩ - това са и най-развиващите се в иновационно отношение държави по отношение на новите мрежови технологии. Най-много заявки за търсене има по отношение на платформите на Амазон, Гугъл и Майкрософт - тези компании са водещи в света по предоставяне на подобен тип услуги. При търсене на съдържание в системата Google insights се вижда, че информационен индекс на cloud в Индия е 100, Сингапур - 62, Тайван - 38 и САЩ - индекс 23. В България, например, този индекса е 0, т. е. интересът е сведен до минимални стойности и не може да бъде изчислен.
Cloud computing заема значително място и в публикациите на Ройтерс и се смята за технология на бъдещето. По темата на страницата на агенцията има над 2500 материали и отправки. Infoworld[4], водещо електронно списание в света по нови комуникационни технологии дефинира предимствата на "компютърен облак" и отбелязва, че това е актуализирана версия на общественополезни компютърни услуги, базирани на виртуални сървъри, достъпни до бизнеса чрез Интернет. Понятието се свързва с всички ИТ модели, ориентирани към предоставяне на услуга срещу заплащане в реално време. Типични представители са приложенията на Google Apps и Zoho Office. Компютърен облак се свързва със 7 основни типа услуги: 1. Софтуер като услуга. 2. Виртуализирани ресурси, достъпни в мрежата и специални центрове за данни. 3. Платформи като услуга-изграждане на приложения, които се изпълняват от инфраструктурата на компанията-доставчик и предават до потребителите чрез Интернет. 4. Мрежови услуги, интегрирани в облака от типа на Google Maps, ADP payroll processing, Postal Service, Bloomberg. 5. MSP или управление на услугата на доставчика – приложения, които изпълняват следните функции: сканиране за вируси, осигуряване на елктронна поща, анти-спам услуги, контрол на трафика, управление на десктопа. 6. Търговска платформа, обединяващи услугите SaaS и MSP - позволява на потребителя да планира пътуване, административни услуги, доставки на пратки и ценообразуване. 7. Интегрирани Интернет услуги или наречени още "bus in the cloud", като се предоставят възможности от типа на "Централна гара". Примери за подобни програми са CapeClear, ESB, OpSource и Boomi/ http://clouddataanalytics.ulitzer.com/node/586446/ Експертите обясняват, че технолoгията ще промени из основи икономиката, бизнеса и методите за aнализ на масивите от данни. Впоследствие това ще доведе и до промяна на централизирания модел на дигиталните медии. Някои от предимства на тази технология[5] са следните: o осигуряване на масивни паралелни подходи за обработка на данните; o бърз автоматичен достъп до информация и данни (данните могат да се възстановяват автоматично при евентуална загуба); o осигуряване на виртуализирана, информационна среда и конкурентни предимства за бизнеса; o компресиране на данните и намаляване разходите за съхраняване на информациия от 2 до 5 пъти; o минимализиране на системите за съхранение на данни, времето за трансфер и осигуряване повече стандартизирани модели за връзка между отделните офиси. Базови характеристики на тези нови технологии: запазване анонимнността на потребителите; картографиране на данни; визуализация на данни; непрекъснато актуализиране на софтуера на потребителя; активно използване на платформата HTML5; интегриране на всички мрежови процеси; даване възможност за проследяване на стари версии на документи и връщане назад. Мрежата "компютърен облак" съдържа 5 основни слоя[6]: клиент, приложен слой, платформа, сървър и инфраструктура. Технологията може да съществува в четири основни форми, наречени: публичен облак; социален облак; частен и хибриден. В платформите са включени различни компоненти, които взаимодействат помежду си. Терминологията в тази област започва да се създава през 60-те години на 20. век.Терминът "cloud"се взаимства от телефонната телекомуниационна индустрия, като компаниите в областта предлагат на клиентите специален телефонен кръг: клиент-клиент и виртуални чaстни мрежи (VPN), тези услуги са с високо качество и на относително ниски цени. По-късно съществен дял в разработване на технологията има компанията "Amazon". Позволява се на потребителя да има достъп до системата с помощта на браузър, независимо къде се намира и какво устройство използва - компютър или мобилен телефон. Услугите в тази сфера нарастват с 483% само в интервала 2008-2009 г., регистрирани са и 116 запазени марки в областта. В изследванията се включват и поредица университети като Масачузетски институт, Университетите в Мелбърн, Бостън, Йел, Калифорния, Минесота, Вашингтон. През 2008 г. компаниите „Интел”, „Яху” и „Хюлед Пакър” създават глобален, многоспектърен център за данни, базиран на отворен код, наречен "Open Cirrus", предназначен е още да насърчава изследванията в сферата. Партньори на проекта са и поредица от Международни институти и университети в САЩ, Филипините, Малйзия и Корея. Схемите по-долу изобразяват основни процеси, свързани с технологията и фирмите, които ги поддържат.
http://www.oncloudcomputing.com/en/2009/09/cloud-computing-architecture-cloud-computing-technology/ Технологията "компютърен облак" включва още 3 основни, характерни услуги: а/ Софтуер под формата на услуги(SaaS); б/ Инфраструктура като услуга(IaaS); в/ Плaтформи за услуги(PaaS). Към първата група спадат програми от типа на: zoho; pixlr; netsuite ;docs; aviary; salesforce; jaycut; acrobat.com;Animoto;Oracle on demand. Инфраструктурата включва виртуални и физически сървъри, където се осигуряват програми, приложения за краен потребител и възможности за интегрирано качване и редактиране на съдържание. Примери за подобна технология са: Amazon Web Services, Gogrid, Sun Grid Compute Utility, Google Base. Най-популярните платформи в света са: AppEngine, amаzon/EC2/;Force.com; Azure Services Platform,Oracle SaaS platform,Coghead, force.com,Yahoo developer network. Компютърен облак се дефинира от Ай Би Ем като нововъзникващ модел за комуникация, където данните и услугите се концентрират и намират в масивни центрове за данни и може да бъде осигурен повсеместен достъп от всяка точка чрез Интернет. Осигурени са и добре разработени приложения, пoдобни технологии се разработват от Amazon/EC2/ http://aws.amazon.com/ec2/.м Платформата на Google се нарича App Engine, Microsoft разработвяа Windows Azure. Така например, технологията „компютърен облак” на Yahoo –Hadoop е специално място за съхранение на знание в съвременните мрежи, запазено под формата на текст, видео, снимки и аудио-файлове. Достъпът до тази структурирана инфомация е публичен и се осъществява от всяка Интернет точка. Hadoop е специален проект, базиран на сървъри от типа Apache Lucene и използва отворена Java платформа. За целта Yahoo през 2006 г. започва да изгражда инфраструктура, включваща 38 000 уеб-сървъра, като в проекта се включват хиляди дизайнери, доставчици и ИТ специалисти. През 2009 г. са създадени 3 бета информационни платформи от типа на Oozie, Hadoop Security и специални, търсещи информация машини (workflow engines). Всички ресурси са с отворен код и достъпни за инсталиране от потребителите в бизнеса, както и в медиите. Тоест, рамката вече е зададена, сега остава да се запълни с подходящо, добре структурирано съдържание. От тази гледна точка основните услуги, предлагани за бизнеса и медиите са: система за събиране, обработка и доставка на данни; мрежа за съхранение и разпространение на файлове с възможности за публичен достъп; складове за данни с осигурени приложения за търсене и обобщаване на информация, свързана с бизнеса; софтуерна рамка за изграждане на информационни кластери и визуализиране на данни; и услуги за координирано управление на съдържание. Yahoo задава рамката на съвременен модел за съхранение и структуриране информация в компютърен облак с широки възможности за достъп и намиращ приложения както в бизнеса, така и в съвременните медии. Тоест съществуващата в момента практика на отделни уеб-страници, с недобре структурирана инфомация, трябва да бъде трансформирана в нещо ново (от типа на RDF, databases) и лесно достъпно до всички потребители и с минимални разходи и ресурси. Компютърен облак - обобщени характеристики Може да се твърди, че компютърен облак е нов модел за съхранение и споделяне на знание и информация, за разлика от традиционните информационни и компютърни технологии. В последните 50 години ИТ притежаваха следните характерни черти: @ инфраструктурен модел - централизирани компютърни услуги, взаимодействие клиент-сървър, Интернет и мобилни компютърни платформи; @ технологични абстракции като - операционни системи, база данни, приложни компоненти, услуги, ориентирани към архитектури; @ приложни домейни от типа на - персонална продуктивност и взаимодействие, специфични индустриални платформи, бизнес приложения; @ модел на услуги като инфраструктури, приложни мениджърски услуги. Тоест, наблюдава се преминаване от консуматорско поведение, характерно за web 1.0 и web 2.0 технологиите, създаващи илюзия за неизчерпаеми ресурси, винаги налични и достъпни, към лесни за управления услуги чрез Интернет, като в момента този модел се развива в посока мобилни комуникации. Технологията и модела на "компютърен облак" променя както модела за комуникация, така и софтуера и достъпа до ресурси като се ориентират потребителите към по-гъвкав софтуер, инфраструктура, модели за правене на бизнес. Достъпът до ресурси става по-динамичен, програмите са виртуални и налични при възникване на необходимост. Перспективи за Cloud computing[7] @ модел за компютърни услуги при поискване; @ разделяне на услуги за дизайн и приложение; @ автоматизирана ситема за разполагане и подреждане на съдържание; @ заплащане за използване на услуга в момента; @ динамичен, многоплатформен достъп до различни модели за информация; @ неизчерпаеми ресурси при поискване; @ промяна моделите на медиите и системите за електронно обучение. Принципи: · точен размер на услугата; · ограничаване на разнообразие (повече услуги - централизирано управления и големи разходи); · споделяне на ресурси; · еластичност; · бързина на услугите; · прогнозируемост; ·
системна интеграция и консултации. Някои популярни определения на комуникациите от типа компютърен облак, записани в системата за извличане на знание от google сa:
Бележки [1] Forrester Research http://www.forrester.com/Research/Document/Excerpt/0,7211,45257,00.html 10.07.2008 [2] Вж. The Data Mining Wiki - http://www.The-Data-Mine.com. [3] „How communicators can fight information overload” Eppler Martin, Mengis Jeanne. CW, volume 26, May-June 2009, pp.4-6” [4] http://www.infoworld.com/d/cloud-computing/what-cloud-computing-really-means-031/септември,2010/ [5] Cloud Computing: Making Analytics in the Cloud a Reality-www.ulitzer.com/node/586446. [7] Harrick Vin;V. Srinivasa Raghavan;K Ananth Krishnan Chief Technology Officer, Tata Consultancy Services (TCS). http://www.tcs.com/industries/media/Pages/default.aspx
|
||||||||||||||||||||